
This series is about making the beginner-to-advance topics in reinforcement learning easy for everyone. We are starting with the basics however if you need to jump to a later part in the series then please go ahead.
What is Reinforcement Learning ?
Reinforcement learning is learning what to do – how to map situations to actions so as to maximize a numerical reward signal. The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them. – Richard S. Sutton
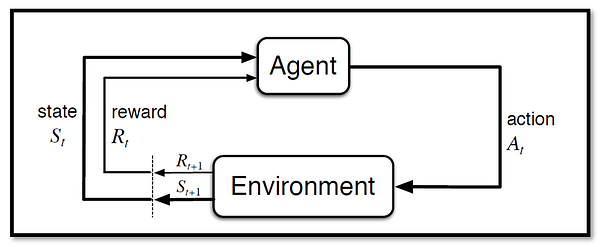
It is pretty simple, an agent (you will create) takes an action in an environment. As feedback, the agent receives a reward & next state of the environment. Here agent will learn by trial & error approach while interacting with the environment.
Understand with an Example:
Lets understand Reinforcement Learning from the point of view of Conor Mcgregor.

Agent: Conor Mcgregor.
Environment: Octagon or UFC fighting ring, I am including Khabib to be a part of the environment.
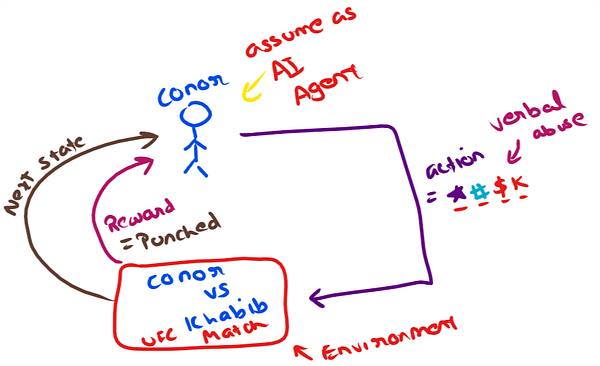
Action: Action taken by the agent in a point in time like abusing khabib “#@$*#%”
Reward: Agent received a punch representing a negative reward here.
Next State: Mach continue for the agent to take more actions in the environment.
The learner is not told which actions to take but instead must discover which actions yield the most reward by trying them. Two distinguishing features of reinforcement learning are trial-and-error search and delayed reward-Richard S. Sutton
Couple of Pointers
- Reinforcement learning is different from unsupervised learning as reinforcement learning is trying to maximize a reward signal instead of trying to find hidden structure.
- Agent is interacting over time with its environment to achieve
a goal. - Exploration & Exploitation Trade-off: To maximize the reward, an agent should use (exploit) those actions that had worked in the past.
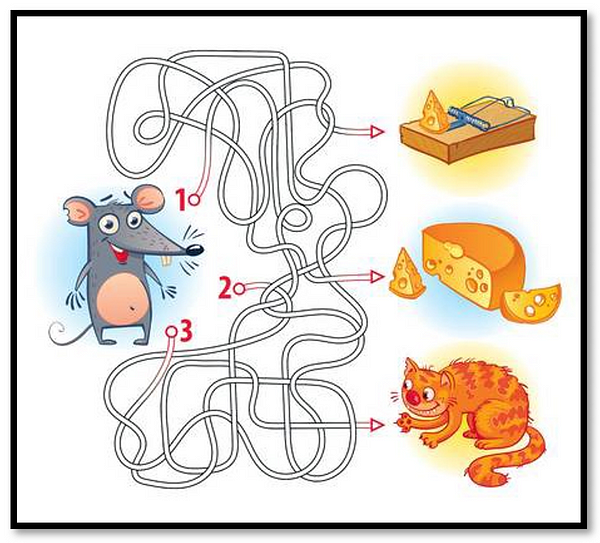
However, to be able to know all the actions resulting in maximized reward, the agent should try (explore) new actions which were not previously taken.
These new actions may lead the agent to a new unexplored major reward (big cheese)or may lead the mouse to the hungry cat 😐
4. Delayed reward:
Andras Adorjan vs Istvan Polgar, 1972- While playing chess a grad master may sacrifice a queen to gain an advantage leading to a victory after 10 moves giving him a delayed reward.

Lets continue in the part 2, where we will learn about policy & value functions.
References –
- Reinforcement Learning, Second Edition by Richard S. Sutton & Andrew G. Barto
If you have any comment or question, then do write it in the comment.
To see similar post, follow me on Medium & Linkedin.
If you enjoyed then Clap it! Share it! Follow Me!!
Join Discussion
5 Comments
I really love your site.. Great colors & theme. Morganne Hermie Baudelaire
Right here is the right website for anyone who wants to understand this topic. Silva Fremont Mayeda
Your style is so unique in comparison to other folks I’ve read stuff from. Many thanks for posting when you’ve got the opportunity, Guess I’ll just book mark this blog. Livia Keith Callum
Really appreciate you sharing this article post. Really looking forward to read more. Fantastic. Morena Codie Lauter
Some genuinely prime articles on this website , saved to fav. Kate Hartley Gora
Your Comment
Leave a Reply Now