
Note: This article is under writing
This article is in continuation to Beginner to Advance: Having fun with Reinforcement learning #1. In this article we will cover more basics of reinforcement learning like policy, value, state, model, type of task and evolutionary method.
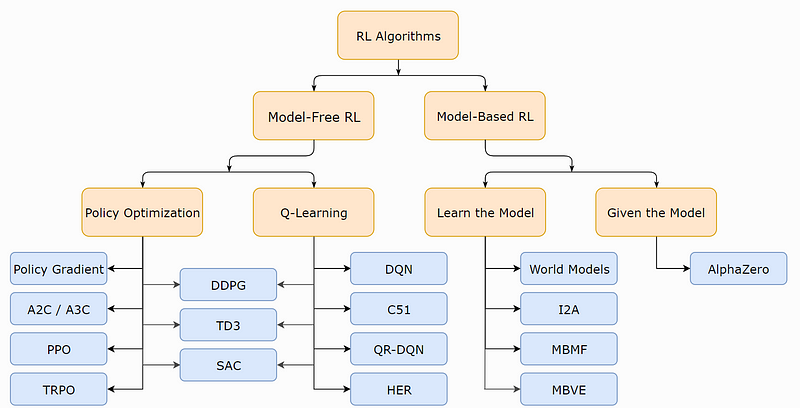
Sub-elements of a Reinforcement Learning System
Beyond the agent and the environment there are four main sub-elements of a reinforcement learning system .
- Policy
- Reward
- Value function
- Model of the environment (optional)
Policy
A policy is a rule used by an agent to decide what actions to take. The policy defines the behavior of the learning agent interacting with the environment at a given time.
Policy can be deterministic or stochastic.

Policy is essentially the agent’s brain, it’s common to substitute the word “policy” for “agent”, eg saying “The policy is trying to maximize reward.”

We often denote the parameters of a policy by theta, and then write this as a subscript on the policy symbol to highlight the connection.
Two common type of stochastic policies are categorical policies and diagonal Gaussian policies. Categorical policies can be used in discrete action spaces, while diagonal Gaussian policies are used in continuous action spaces.
Reward
Upon taking an action in the environment, the learning agent receives a feedback signal from the environment called as Reward or Reward Signal. A reward signal defines the goal of reinforcement learning problem.
Objective of the agent is to maximize the total amount of reward it receives.
If an action selected by the policy leads to low reward then the policy may change to select another action in future for that sate which returns a higher reward.
Value function
Value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. It is opposite to reward which is short termed.
Reward signal indicates what is good in an immediate sense, a value function specifies what is good in the long run.
It is possible that a state leads to low immediate reward but have a higher value. It might be leading to a sequence of future states which result in a higher cumulative reward or vice-versa. Purpose of estimating values is to achieve more reward.
Efficiently estimating the value is extremely important in Reinforcement learning algorithms.
Model-based vs Model-free methods:

Model-based learning attempts to model the environment then choose the optimal policy based on it’s learned model; In Model-free learning the agent relies on trial-and-error experience for setting up the optimal policy.
More Terminologies
- Action Space: Set of valid actions in an environment is called action space. It can be of two type discrete or continuous.
- Discrete action space: The agent decides which distinct action to perform from a finite action set.
- Continuous action space: Actions are expressed as a single real-valued vector
- State: State will informally translate to whatever information is available to the agent about the environment.
All reinforcement learning agents have explicit goals, can sense aspects of their environments, and can choose actions to influence their environments.- Richard S. Sutton
5. Type of Tasks:


Episodic Tasks: In such type of tasks agent-environment interaction can be broken into episodes having a terminal state (one or many) followed by a reset to a standard starting position.
While playing Mario terminal stage can be falling into the pit or winning the game. Next episode will start independently of how the previous one ended.
Continuing Tasks: In such tasks, there are no identifiable episodes and the agent-environment interaction goes on infinitely or we decide to stop it.
6. Evolutionary methods: Solutions such as genetic algorithms never estimate value function. An evolutionary method keeps the policy fixed and plays many games against the opponent or simulate many games using a model. Here frequency of win gives an estimated probability of winning using the policy. After many games, if needed change in policy is made.
Difference between Evolutionary methods & Value function:
If the learning agent wins the overall game then all the moves made in the game optimal/ non-optimal are given credit in evolutionary methods, specific moves leading to victory are not given credit.
Value function method, in contrast, takes advantage of information available during the course of play & gives credit to individual states in the game.
7. Action-value (Q): Similar to value but it takes current state as an extra parameter.
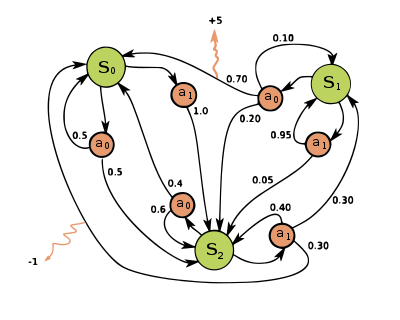
8. Markov decision process: MDP provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker.
MDPs are useful for studying optimization problems solved via dynamic programming and reinforcement learning.
Markov property implies that the properties of random variables related to the future depend only on relevant information about the current time, not on information from further in the past. A random process with the Markov property is called Markov process.
The core problem of MDPs is to find a “policy” for the decision maker.

9. Stochastic or random process is a mathematical object usually defined as a family of random variables( an object is anything that has been (or could be) formally defined).
Stochastic process representing numerical values of some system randomly changing over time, such as the growth of a bacterial population, an electrical current fluctuating due to thermal noise, or the movement of a gas molecule — Wikipedia
10. Dynamic programming: In terms of mathematical optimization, dynamic programming usually refers to simplifying a decision by breaking it down into a sequence of decision steps over time. This is done by defining a sequence of value functions
Lets continue in the part 3, where we will deep dive into RL
References –
- Reinforcement Learning, Second Edition by Richard S. Sutton & Andrew G. Barto
- openai.com
- Wikipedia.org
If you have any comment or question, then do write it in the comment.
To see similar post, follow me on Medium & Linkedin.
If you enjoyed then Clap it! Share it! Follow Me!!
Join Discussion
2 Comments
Your style is really unique compared to other folks I have read stuff from. I appreciate you for posting when you have the opportunity, Guess I will just bookmark this blog. Crystal Jason Othelia
I believe what you typed made a great deal of sense. Darb Garreth Meehan Christal Rabi Hatcher
Your Comment
Leave a Reply Now